IceFormer: Accelerated Inference with Long-Sequence Transformers on CPUs
Abstract
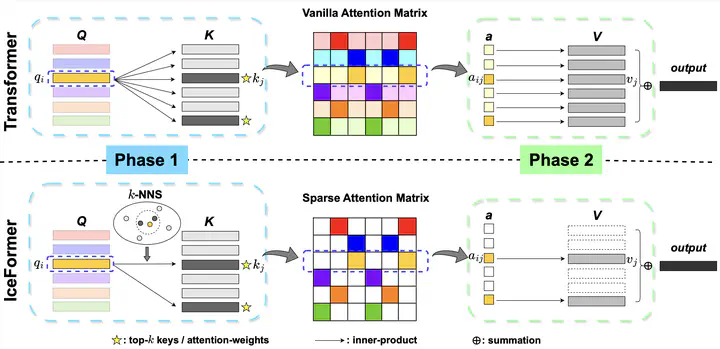
One limitation of existing Transformer-based models is that they cannot handle very long sequences as input since their self-attention operations exhibit quadratic time and space complexity. This problem becomes especially acute when Transformers are deployed on hardware platforms equipped only with CPUs. To address this issue, we propose a novel method for accelerating self-attention at inference time that works with pretrained Transformer models out-of-the-box without requiring retraining. We experiment using our method to accelerate various long-sequence Transformers, including a leading LLaMA 2-based LLM, on various benchmarks and demonstrate a greater speedup of 2.73x - 7.63x while retaining 98.6% - 99.6% of the accuracy of the original pretrained models. The code is available on our project website at https://yuzhenmao.github.io/IceFormer/.
@inproceedings{
mao2024iceformer,
title={IceFormer: Accelerated Inference with Long-Sequence Transformers on {CPU}s},
author={Yuzhen Mao and Martin Ester and Ke Li},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=6RR3wU4mSZ}
}
Yuzhen Mao
Affiliated members/collaborators
My research interests include Large Language Models and Graph Neural Nets.
Ke Li
Professor of Computer Science
My research interests include Machine Learning, Computer Vision and Algorithms.