Adaptive IMLE for Few-shot Pretraining-free Generative Modelling
Abstract
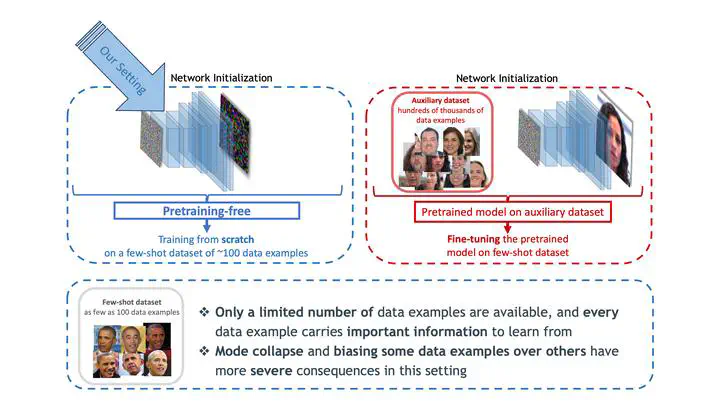
Despite their success on large datasets, GANs have been difficult to apply in the few-shot setting, where only a limited number of training examples are provided. Due to mode collapse, GANs tend to ignore some training examples, causing overfitting to a subset of the training dataset, which is small in the first place. A recent method called Implicit Maximum Likelihood Estimation (IMLE) is an alternative to GAN that tries to address this issue. It uses the same kind of generators as GANs but trains it with a different objective that encourages mode coverage. However, the theoretical guarantees of IMLE hold under a restrictive condition that the optimal likelihood at all data points is the same. In this paper, we present a more generalized formulation of IMLE which includes the original formulation as a special case, and we prove that the theoretical guarantees hold under weaker conditions. Using this generalized formulation, we further derive a new algorithm, which we dub Adaptive IMLE, which can adapt to the varying difficulty of different training examples. We demonstrate on multiple few-shot image synthesis datasets that our method significantly outperforms existing methods. Our code is available at https://github.com/mehranagh20/AdaIMLE.
Add the publication’s full text or supplementary notes here. You can use rich formatting such as including code, math, and images.
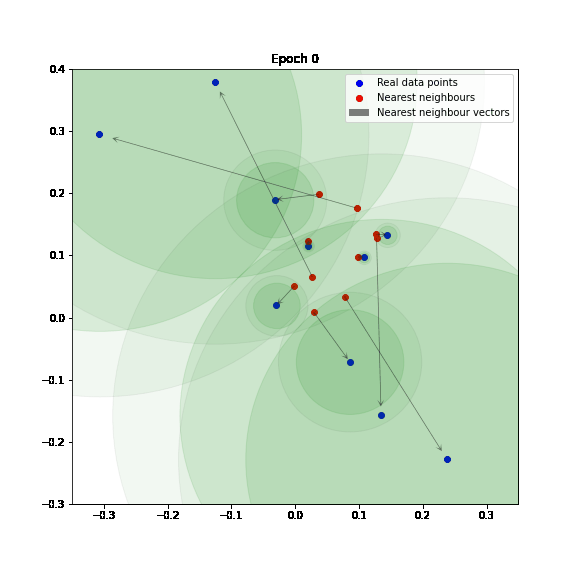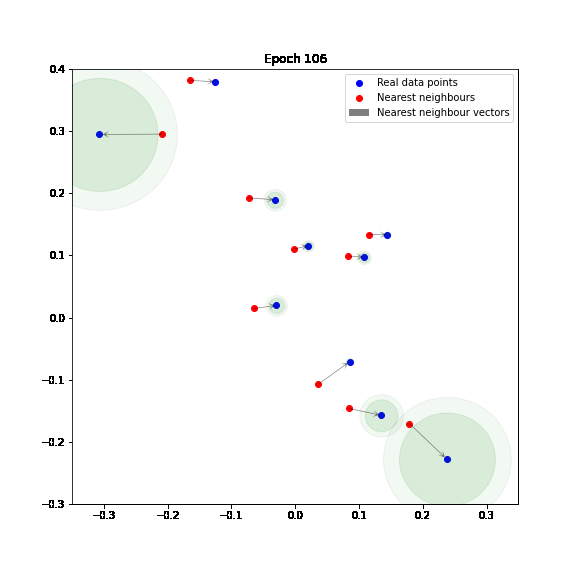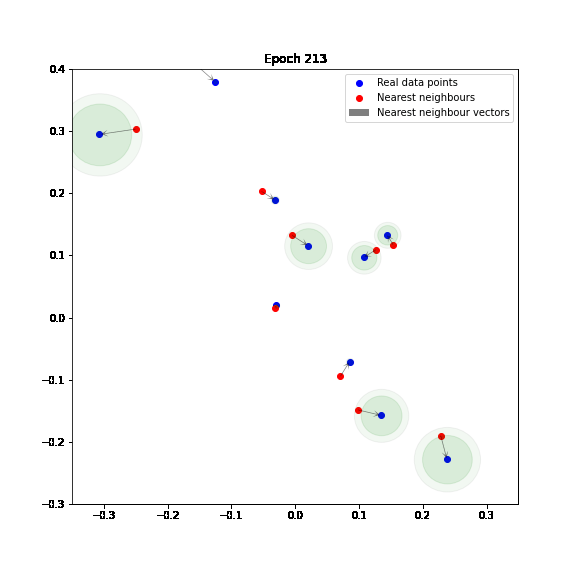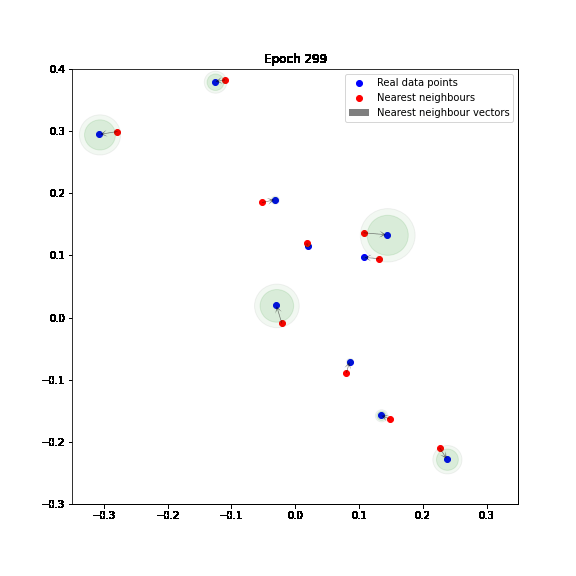
In the following figure, we can see how the Adaptive IMLE algorithm shrinks neighbourhoods around data points in a toy example. You can find a jupyter notebook that includes a basic implementation of Adaptive IMLE here.
If you find our work useful in your research, please consider citing:
@inproceedings{aghabozorgi2023adaimle,
title={Adaptive IMLE for Few-shot Pretraining-free Generative Modelling
},
author={Mehran Aghabozorgi and Shichong Peng and Ke Li},
booktitle={International Conference on Machine Learning},
year={2023}
}
Mehran Aghabozorgi
Ph.D. Student
My research interests include Generative modeling and Reinforcement Learning.
Shichong Peng
Ph.D. Student
My research focuses on generative model and 3D neural rendering. My goal is to develop methods that can better aid 3D object generation and animation.
Ke Li
Professor of Computer Science
My research interests include Machine Learning, Computer Vision and Algorithms.